
Justicia Ciega oye tu corazón
Dataset
https://www.kaggle.com/datasets/kinguistics/heartbeat-sounds?utm_source=chatgpt.com
Con este código:
# ============================================================
# CARDIO IA - JUSTICIA CIEGA
# IA PARA DETECTAR LATIDOS CARDÍACOS
# KAGGLE NOTEBOOK SIMPLE Y FUNCIONAL
# ============================================================
# ============================================================
# 1. IMPORTAR LIBRERÍAS
# ============================================================
import os
import numpy as np
import matplotlib.pyplot as plt
import librosa
import librosa.display
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (
Dense,
Dropout
)
# ============================================================
# 2. RUTA DEL DATASET
# ============================================================
DATASET_PATH = "/kaggle/input/datasets/kinguistics/heartbeat-sounds"
# ============================================================
# 3. COMPROBAR ESTRUCTURA DEL DATASET
# ============================================================
print("===================================")
print("ESTRUCTURA DEL DATASET")
print("===================================\n")
for dirname, _, filenames in os.walk(DATASET_PATH):
print(dirname)
for filename in filenames[:3]:
print(" ", filename)
# ============================================================
# 4. DEFINIR RUTAS
# ============================================================
NORMAL_PATH = os.path.join(
DATASET_PATH,
"set_a"
)
ABNORMAL_PATH = os.path.join(
DATASET_PATH,
"set_b"
)
print("\n===================================")
print("RUTAS")
print("===================================\n")
print("SET_A:")
print(NORMAL_PATH)
print("\nSET_B:")
print(ABNORMAL_PATH)
# ============================================================
# 5. FUNCIÓN PARA EXTRAER CARACTERÍSTICAS
# ============================================================
def extract_features(file_path):
try:
# CARGAR AUDIO
audio, sample_rate = librosa.load(
file_path,
sr=None
)
# EXTRAER MFCC
mfccs = librosa.feature.mfcc(
y=audio,
sr=sample_rate,
n_mfcc=40
)
# MEDIA DE LAS CARACTERÍSTICAS
mfccs_processed = np.mean(
mfccs.T,
axis=0
)
return mfccs_processed
except Exception as e:
print("\nERROR EN:")
print(file_path)
print(e)
return None
# ============================================================
# 6. CREAR LISTAS
# ============================================================
features = []
labels = []
# ============================================================
# 7. CARGAR SET_A = SANO
# ============================================================
print("\n===================================")
print("CARGANDO SET_A")
print("===================================\n")
for file in os.listdir(NORMAL_PATH):
if file.endswith(".wav"):
file_path = os.path.join(
NORMAL_PATH,
file
)
data = extract_features(file_path)
if data is not None:
features.append(data)
labels.append("sano")
print("SET_A cargado.")
# ============================================================
# 8. CARGAR SET_B = NO SANO
# ============================================================
print("\n===================================")
print("CARGANDO SET_B")
print("===================================\n")
for file in os.listdir(ABNORMAL_PATH):
if file.endswith(".wav"):
file_path = os.path.join(
ABNORMAL_PATH,
file
)
data = extract_features(file_path)
if data is not None:
features.append(data)
labels.append("no_sano")
print("SET_B cargado.")
# ============================================================
# 9. RESUMEN
# ============================================================
print("\n===================================")
print("RESUMEN")
print("===================================\n")
print("Audios cargados:")
print(len(features))
print("\nEtiquetas:")
print(set(labels))
# ============================================================
# 10. PREPARAR DATOS
# ============================================================
X = np.array(features)
encoder = LabelEncoder()
y = encoder.fit_transform(labels)
# ============================================================
# 11. DIVIDIR TRAIN Y TEST
# ============================================================
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
print("\n===================================")
print("DATOS")
print("===================================\n")
print("Train:", X_train.shape)
print("Test:", X_test.shape)
# ============================================================
# 12. CREAR RED NEURONAL
# ============================================================
model = Sequential()
# CAPA 1
model.add(Dense(
256,
input_shape=(40,),
activation='relu'
))
model.add(Dropout(0.3))
# CAPA 2
model.add(Dense(
128,
activation='relu'
))
model.add(Dropout(0.3))
# CAPA 3
model.add(Dense(
64,
activation='relu'
))
# SALIDA
model.add(Dense(
1,
activation='sigmoid'
))
# ============================================================
# 13. COMPILAR MODELO
# ============================================================
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
print("\n===================================")
print("MODELO COMPILADO")
print("===================================\n")
# ============================================================
# 14. ENTRENAR IA
# ============================================================
history = model.fit(
X_train,
y_train,
epochs=30,
batch_size=32,
validation_data=(X_test, y_test)
)
# ============================================================
# 15. EVALUAR IA
# ============================================================
loss, accuracy = model.evaluate(
X_test,
y_test
)
print("\n===================================")
print("PRECISIÓN FINAL")
print("===================================\n")
print(accuracy)
# ============================================================
# 16. GRÁFICA DE APRENDIZAJE
# ============================================================
plt.figure(figsize=(10,5))
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title("Aprendizaje de Justicia Ciega")
plt.ylabel("Precisión")
plt.xlabel("Épocas")
plt.legend([
"Entrenamiento",
"Validación"
])
plt.show()
# ============================================================
# 17. FUNCIÓN PARA PREDECIR
# ============================================================
def predict_heart(audio_file):
feature = extract_features(audio_file)
if feature is None:
print("No se pudo analizar el audio.")
return
feature = feature.reshape(1, -1)
prediction = model.predict(feature)[0][0]
print("\n===================================")
print("ANÁLISIS DE JUSTICIA CIEGA")
print("===================================\n")
if prediction > 0.5:
print("⚠️ POSIBLE CORAZÓN ALTERADO")
else:
print("❤️ CORAZÓN SANO")
# ============================================================
# 18. EJEMPLO DE USO
# ============================================================
# DESCOMENTA Y CAMBIA EL ARCHIVO PARA PROBAR
# predict_heart("/kaggle/input/datasets/kinguistics/heartbeat-sounds/set_a/normal__201101051104.wav")da algunos errores pero entrena el modelo:
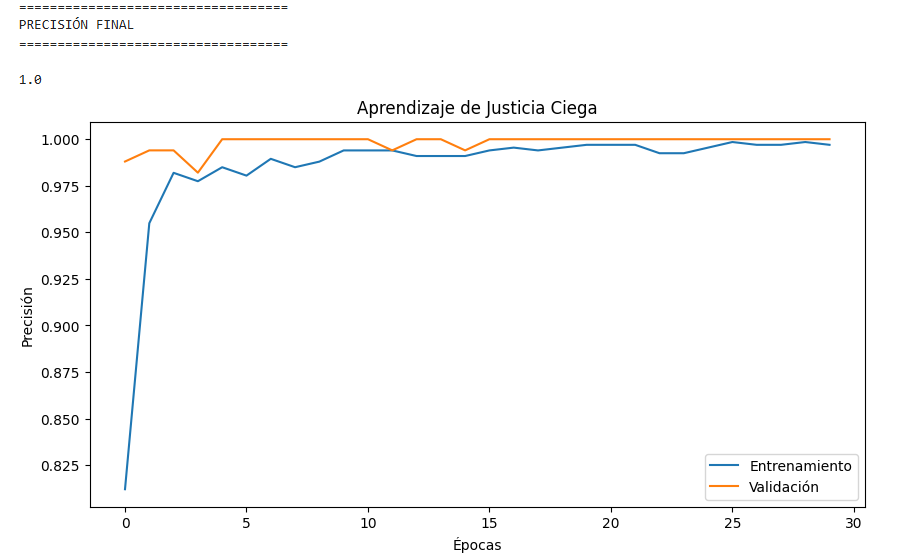
Ahora vamos a probarlo con un archivo real según nos indica al final del código:
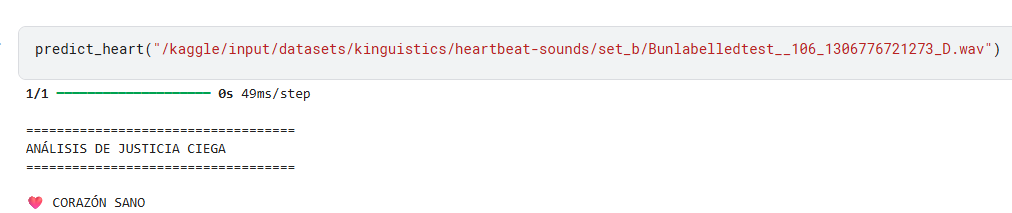
Y creo que lo he hecho al revés porque los del conjunto A son sanos y los del B alterados pero… el sistema funciona.

